Textual
Routines for textual data.
ROVER
Bases: BaseTextsAggregator
Recognizer Output Voting Error Reduction (ROVER).
This method uses dynamic programming to align sequences. Next, aligned sequences are used
to construct the Word Transition Network (WTN):
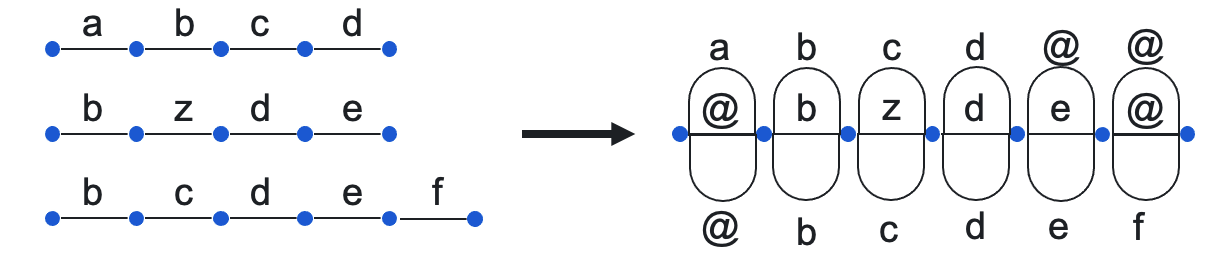 Finally, the aggregated sequence is the result of majority voting on each edge of the WTN.
Finally, the aggregated sequence is the result of majority voting on each edge of the WTN.
J. G. Fiscus, "A post-processing system to yield reduced word error rates: Recognizer Output Voting Error Reduction (ROVER)," 1997 IEEE Workshop on Automatic Speech Recognition and Understanding Proceedings, 1997, pp. 347-354. https://doi.org/10.1109/ASRU.1997.659110
Examples:
>>> from crowdkit.datasets import load_dataset
>>> from crowdkit.aggregation import ROVER
>>> df, gt = load_dataset('crowdspeech-test-clean')
>>> df['text'] = df['text'].str.lower()
>>> tokenizer = lambda s: s.split(' ')
>>> detokenizer = lambda tokens: ' '.join(tokens)
>>> result = ROVER(tokenizer, detokenizer).fit_predict(df)
Attributes:
| Name | Type | Description |
|---|---|---|
texts_ |
Series
|
Tasks' texts.
A pandas.Series indexed by |
Source code in crowdkit/aggregation/texts/rover.py
31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 | |
detokenizer = attr.ib()
class-attribute
instance-attribute
A callable that takes a list of tokens and returns a string.
silent = attr.ib(default=True)
class-attribute
instance-attribute
If false, show a progress bar.
tokenizer = attr.ib()
class-attribute
instance-attribute
A callable that takes a string and returns a list of tokens.
fit(data)
Fits the model. The aggregated results are saved to the texts_ attribute.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data
|
DataFrame
|
Workers' text outputs.
A pandas.DataFrame containing |
required |
Returns:
| Name | Type | Description |
|---|---|---|
ROVER |
ROVER
|
self. |
Source code in crowdkit/aggregation/texts/rover.py
71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 | |
fit_predict(data)
Fit the model and return the aggregated texts.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data
|
DataFrame
|
Workers' text outputs.
A pandas.DataFrame containing |
required |
Returns:
| Name | Type | Description |
|---|---|---|
Series |
Series[Any]
|
Tasks' texts.
A pandas.Series indexed by |
Source code in crowdkit/aggregation/texts/rover.py
108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 | |
TextHRRASA
Bases: BaseTextsAggregator
HRRASA on text embeddings.
Given a sentence encoder, encodes texts provided by workers and runs the HRRASA algorithm for embedding aggregation.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
encoder
|
Callable[[str], ArrayLike]
|
A callable that takes a text and returns a NumPy array containing the corresponding embedding. |
required |
n_iter
|
int
|
A number of HRRASA iterations. |
100
|
lambda_emb
|
float
|
A weight of reliability calculated on embeddigs. |
0.5
|
lambda_out
|
float
|
A weight of reliability calculated on outputs. |
0.5
|
alpha
|
float
|
Confidence level of chi-squared distribution quantiles in beta parameter formula. |
0.05
|
calculate_ranks
|
bool
|
If true, calculate additional attribute |
False
|
Examples:
We suggest to use sentence encoders provided by Sentence Transformers.
>>> from crowdkit.datasets import load_dataset
>>> from crowdkit.aggregation import TextHRRASA
>>> from sentence_transformers import SentenceTransformer
>>> encoder = SentenceTransformer('all-mpnet-base-v2')
>>> hrrasa = TextHRRASA(encoder=encoder.encode)
>>> df, gt = load_dataset('crowdspeech-test-clean')
>>> df['text'] = df['text'].str.lower()
>>> result = hrrasa.fit_predict(df)
Source code in crowdkit/aggregation/texts/text_hrrasa.py
12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 | |
fit_predict(data, true_objects)
Fit the model and return aggregated texts.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data
|
DataFrame
|
Workers' responses.
A pandas.DataFrame containing |
required |
true_objects
|
Series
|
Tasks' ground truth texts.
A pandas.Series indexed by |
required |
Returns:
| Name | Type | Description |
|---|---|---|
Series |
Series[Any]
|
Tasks' texts.
A pandas.Series indexed by |
Source code in crowdkit/aggregation/texts/text_hrrasa.py
93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 | |
fit_predict_scores(data, true_objects)
Fit the model and return scores.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data
|
DataFrame
|
Workers' responses.
A pandas.DataFrame containing |
required |
true_objects
|
Series
|
Tasks' ground truth texts.
A pandas.Series indexed by |
required |
Returns:
| Name | Type | Description |
|---|---|---|
DataFrame |
DataFrame
|
Tasks' label scores.
A pandas.DataFrame indexed by |
Source code in crowdkit/aggregation/texts/text_hrrasa.py
71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 | |
TextRASA
Bases: BaseTextsAggregator
RASA on text embeddings.
Given a sentence encoder, encodes texts provided by workers and runs the RASA algorithm for embedding aggregation.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
encoder
|
Callable[[str], NDArray[Any]]
|
A callable that takes a text and returns a NumPy array containing the corresponding embedding. |
required |
n_iter
|
int
|
A number of RASA iterations. |
100
|
alpha
|
float
|
Confidence level of chi-squared distribution quantiles in beta parameter formula. |
0.05
|
Examples:
We suggest to use sentence encoders provided by Sentence Transformers.
>>> from crowdkit.datasets import load_dataset
>>> from crowdkit.aggregation import TextRASA
>>> from sentence_transformers import SentenceTransformer
>>> encoder = SentenceTransformer('all-mpnet-base-v2')
>>> hrrasa = TextRASA(encoder=encoder.encode)
>>> df, gt = load_dataset('crowdspeech-test-clean')
>>> df['text'] = df['text'].str.lower()
>>> result = hrrasa.fit_predict(df)
Source code in crowdkit/aggregation/texts/text_rasa.py
12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 | |
fit(data, true_objects)
Fit the model.
Args:
data (DataFrame): Workers' outputs.
A pandas.DataFrame containing task, worker and output columns.
true_objects (Series): Tasks' ground truth labels.
A pandas.Series indexed by task such that labels.loc[task]
is the tasks's ground truth label.
Returns:
| Name | Type | Description |
|---|---|---|
TextRASA |
TextRASA
|
self. |
Source code in crowdkit/aggregation/texts/text_rasa.py
55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | |
fit_predict(data, true_objects)
Fit the model and return aggregated texts.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data
|
DataFrame
|
Workers' responses.
A pandas.DataFrame containing |
required |
true_objects
|
Series
|
Tasks' ground truth texts.
A pandas.Series indexed by |
required |
Returns:
| Name | Type | Description |
|---|---|---|
Series |
Series[Any]
|
Tasks' texts.
A pandas.Series indexed by |
Source code in crowdkit/aggregation/texts/text_rasa.py
95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 | |
fit_predict_scores(data, true_objects)
Fit the model and return scores.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
data
|
DataFrame
|
Workers' responses.
A pandas.DataFrame containing |
required |
true_objects
|
Series
|
Tasks' ground truth texts.
A pandas.Series indexed by |
required |
Returns:
| Name | Type | Description |
|---|---|---|
DataFrame |
DataFrame
|
Tasks' label scores.
A pandas.DataFrame indexed by |
Source code in crowdkit/aggregation/texts/text_rasa.py
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 | |